七七转
七七(RemliaTouchou、behod、Nahida、Remlia)1999 年生人,内蒙古兴安盟,听风吟服务器技术,Tick128 开发者,红魔乡 MC 服主,资深 Jvav 全栈开发(助理是 Cursor),东方爱好者,推蕾米莉亚,男娘(装的还挺像,以至于我认为他是女的),听风吟最佳模仿者
2025 年 1 月 | 噩梦开始
当时我在听风吟群里询问服务器问题,七七从听风吟的群里加我(QianMo)为好友声称他能帮我解决问题
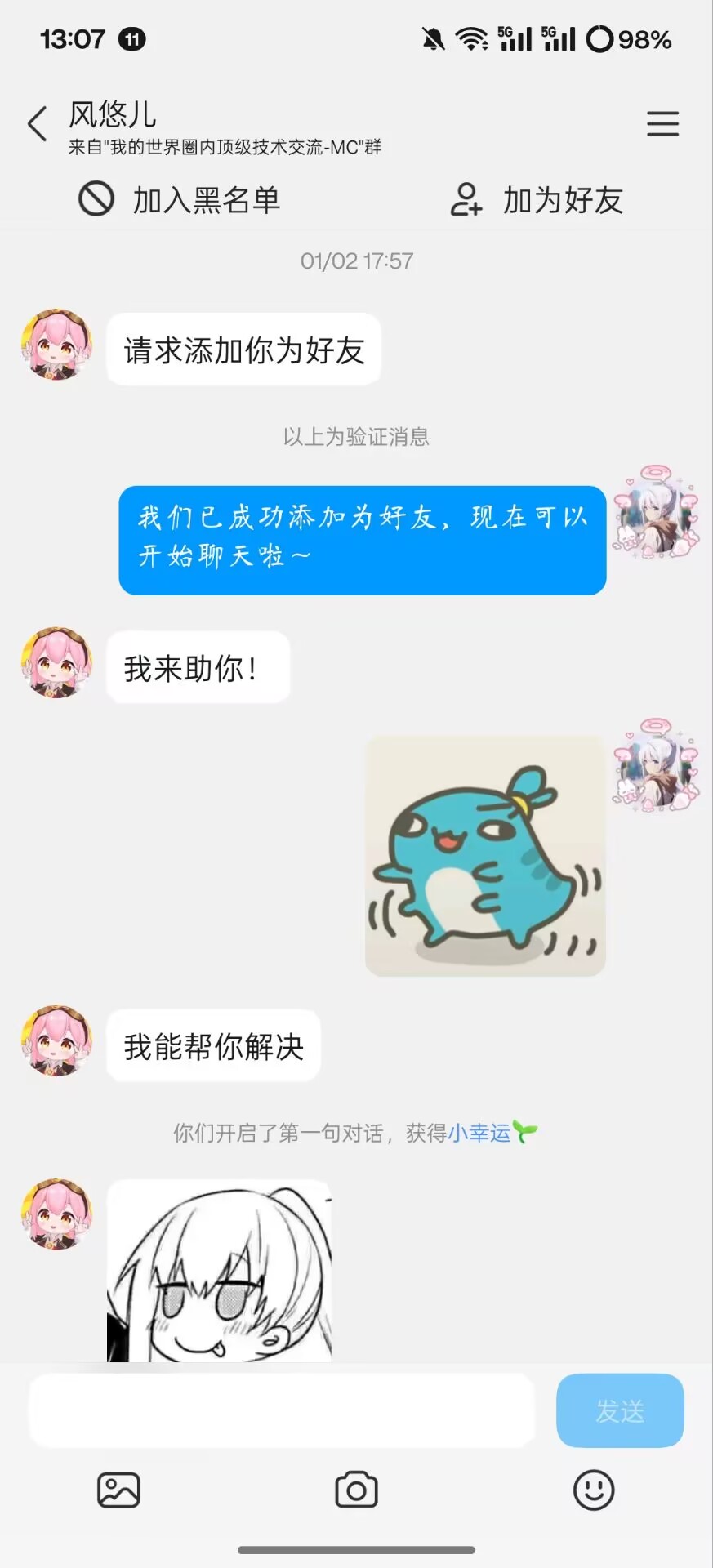
随后他扔给我了一个“Fixer.jar” Bukkit 的插件
慢慢的,他开始无休止的给我打 QQ 电话和戳一戳,试图让我回他消息,我觉得这很恶心...
TODO: 2025 年 1 月~4 月
2025 年 4 月 | Tick128 横空出世
2025 年 4 月 19 日 七七带着他的 Tick128 向我走来了
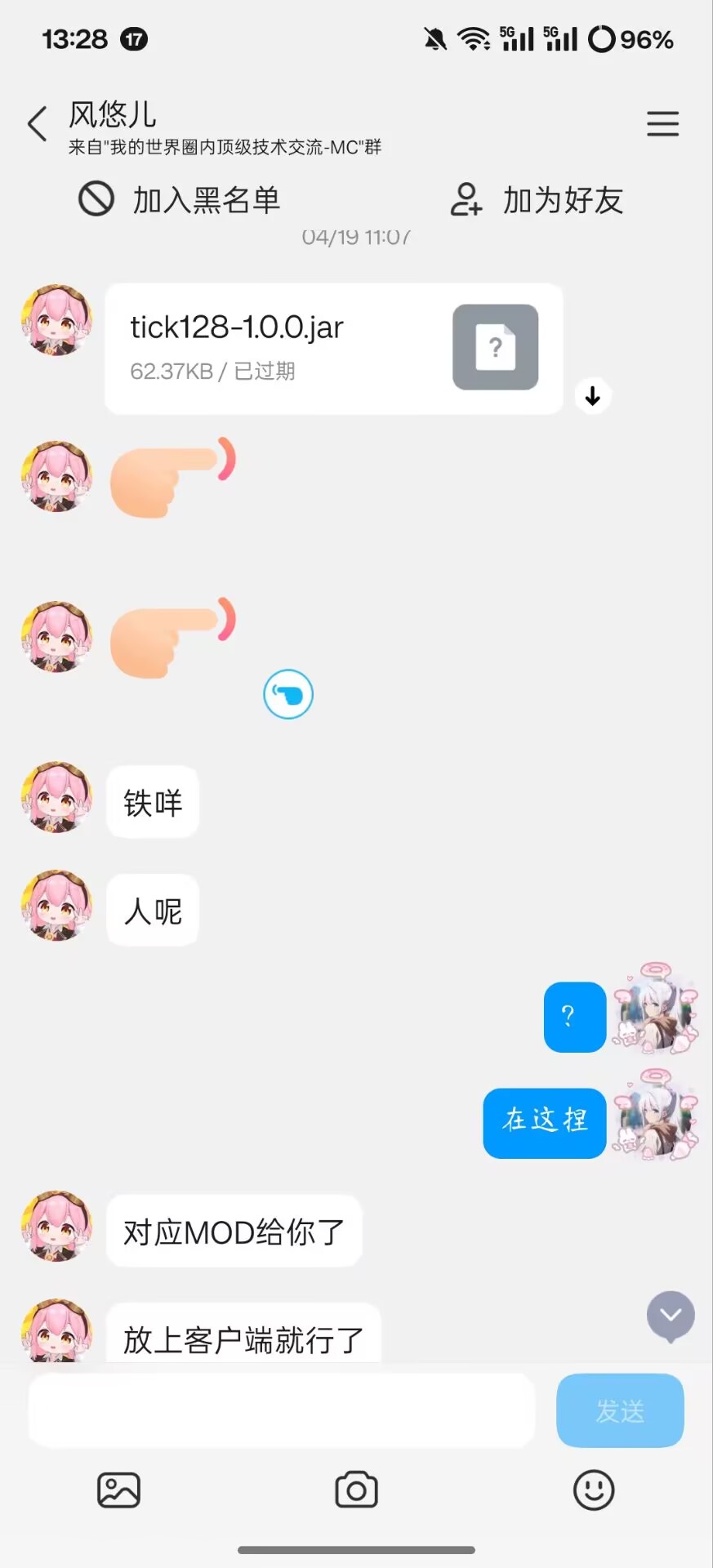
在我服务器进行测试,经过他的一顿忽悠下我居然相信了它又很大的优化效果,MSPT 自动调优,同步渲染...
TODO: 2025 年 4 月~6 月
2025 年 6 月 | 开端
2025 年 6 月 29 日
七七向 alazeprt 推荐了 Tick128 插件
“确实有人买”指 MC:CS2 服务器购买了他的 Tick128 插件
后来 Tick128 不仅免费了还扔到 MCMOD 上了,MC:CS2 服主成功被阴了
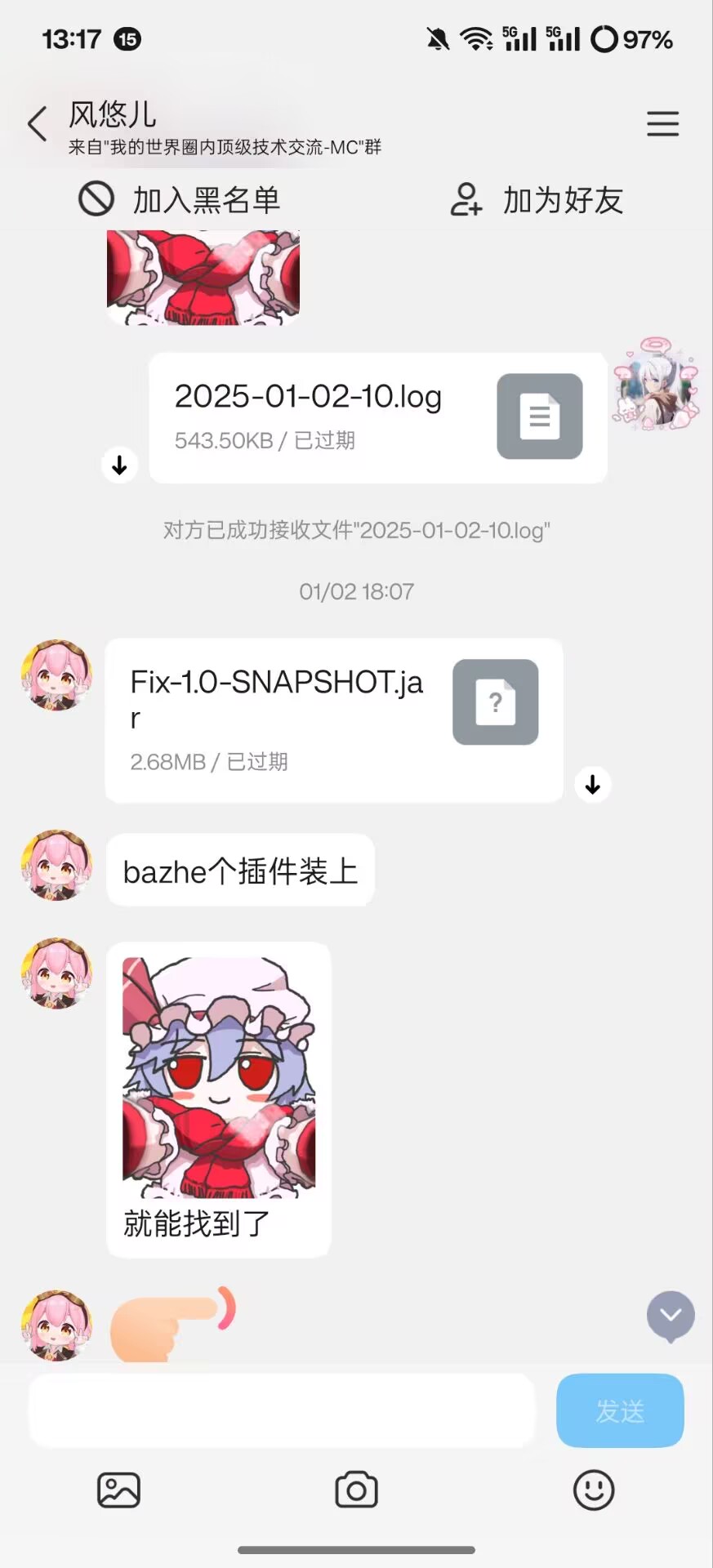
插件里面写个扫 mods 文件夹,笑死我了
但是我也用了好长时间了,才发现我被坑了

听风吟给他推荐了 DeepSeek AI 用来写插件,七七发现并不好用向我询问有没有好用的,我推荐了 Augment,然后他爱不释手了
Vibe Coding 魅力时刻
HaHaWTH 对 Tick128 反编译源码的评价

七七发现 AI 插件的试用到期了,还来求助我问问能不能继续续杯,逆天...
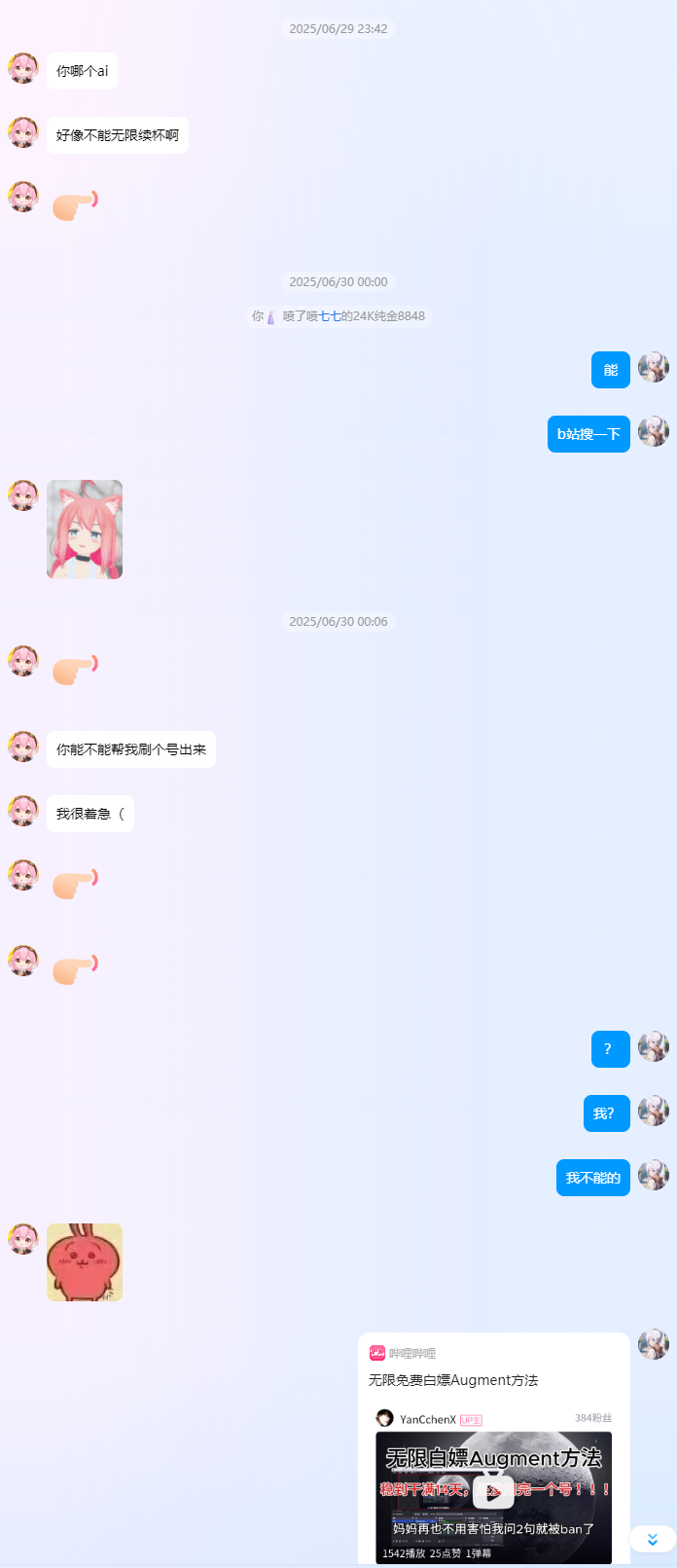
事情告一段落...
2025 年 7 月 | Tick128 火了
2025 年 7 月 13 日
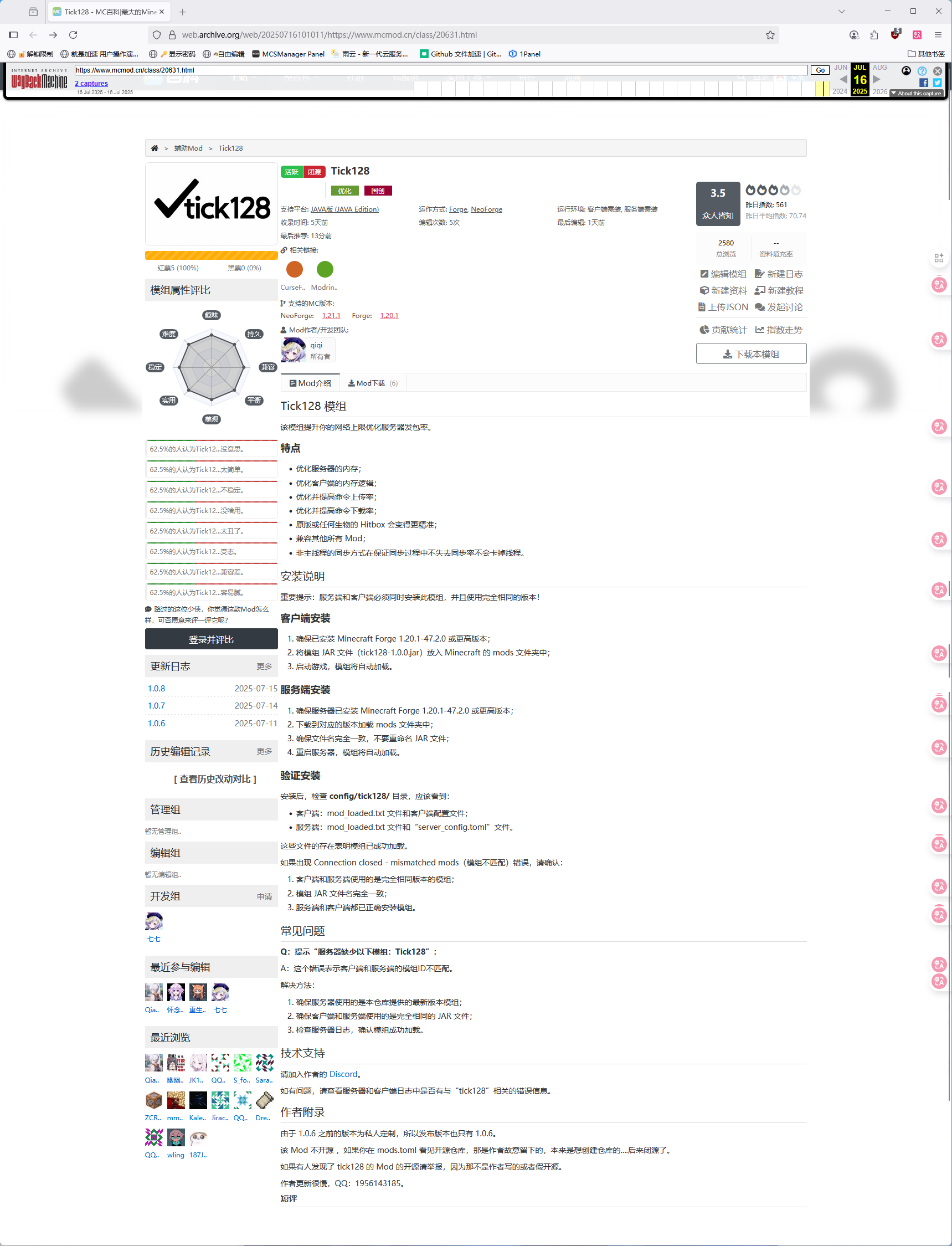
震惊,居然上架 MCMOD 了,但是 Modrinth 没有过审
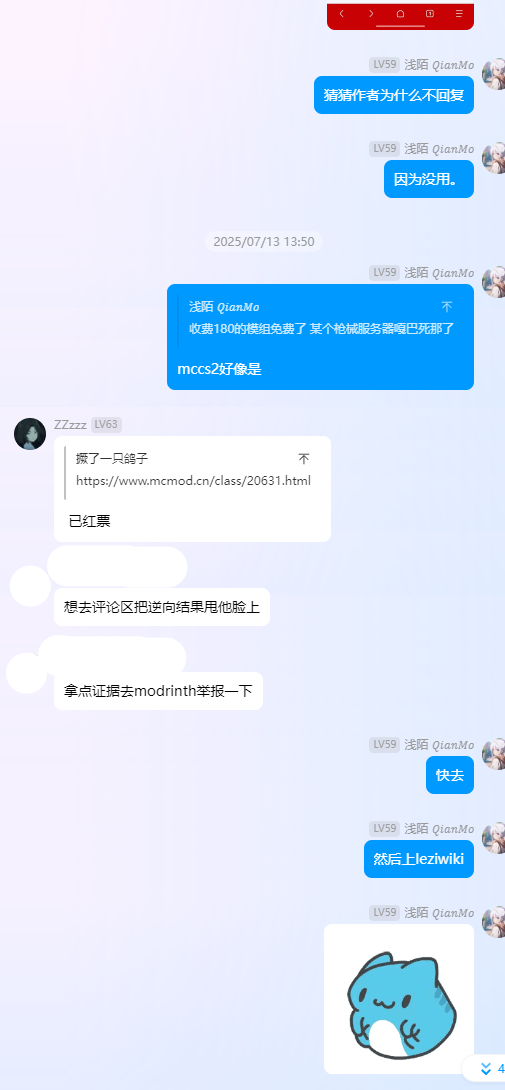
短评区几乎全是串子,串的非常像

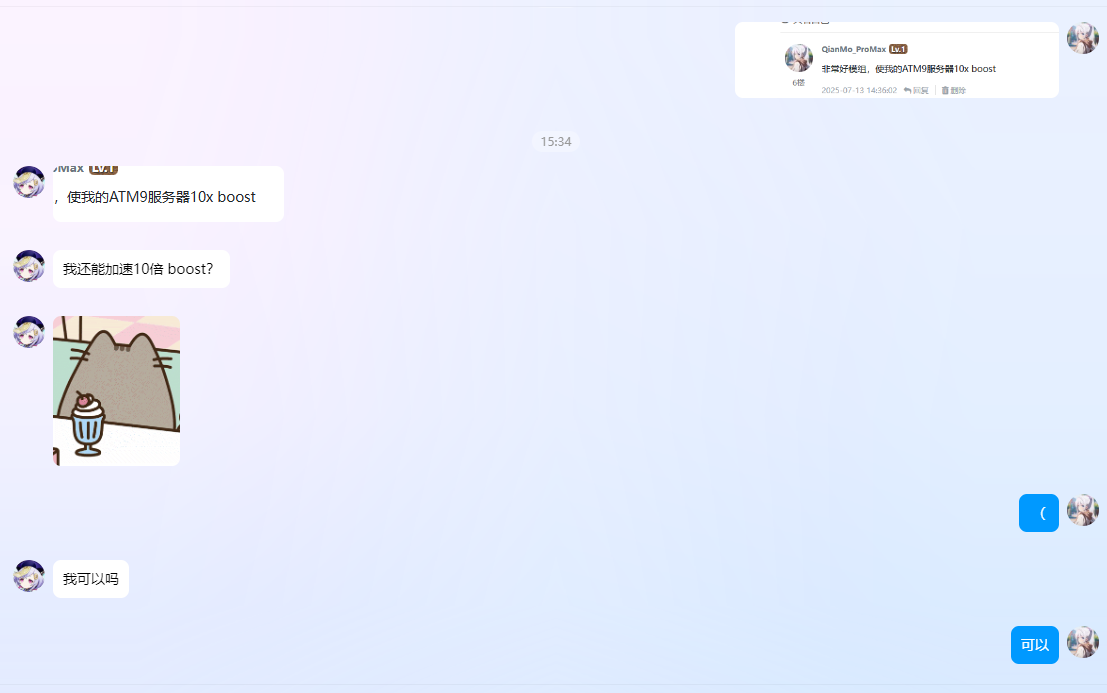
2025 年 7 月 14 日
七七仍然沉浸在自己写的 Tick128 模组的优化效果中
朝天 2500fps 原版就可以做到
脑子确实抽了
野兽先辈

666 优化 FPS 是空壳
硬编码吓哭了
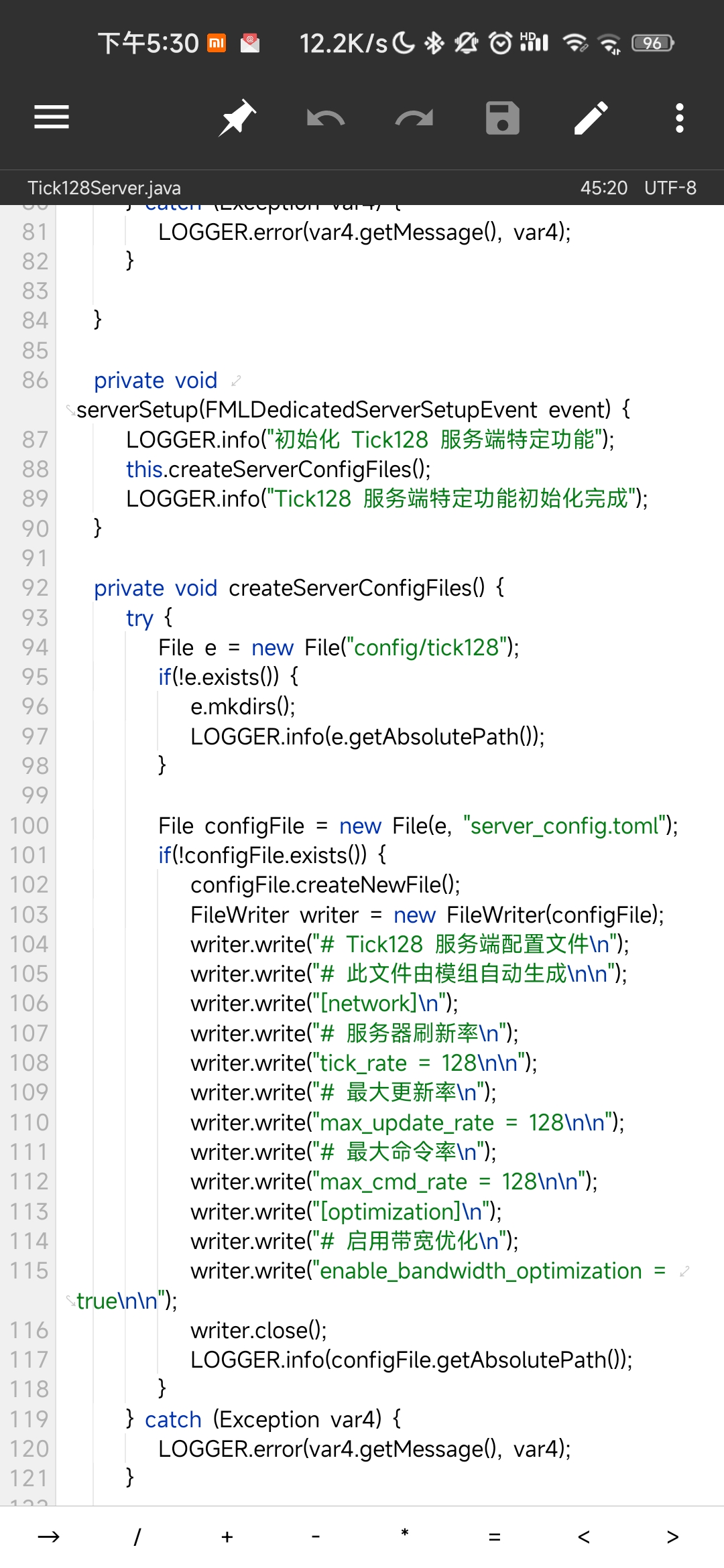
双倍监听,双倍快乐

2025 年 7 月 15 日
震惊,上架 CurseForge 了
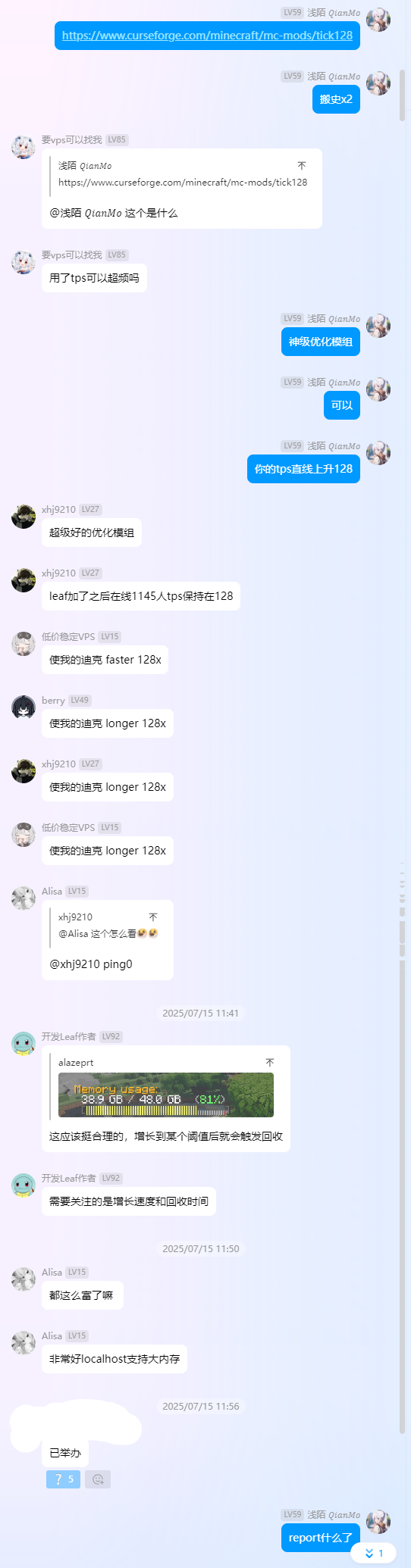
2025 年 7 月 16 日
TODO
来看看 Tick128 的神秘力量吧(来自神秘热心社区人员的高雅 README 编写)
🚀 Tick128 - 革命性 Minecraft 性能优化框架
项目愿景
Tick128 是我经过三年深度研究开发的下一代 Minecraft 性能优化框架。基于对CS2 SubTick 机制的深入理解,结合先进的内存废弃率算法,实现了前所未有的128tick 高频渲染体验。
本项目采用了业界最先进的空方法优化模式和零开销抽象设计理念,确保在提供丰富功能的同时保持极致的性能表现。
💡 核心技术创新
经过大量的性能分析和算法研究,我发现了传统优化方法的根本缺陷:
- 过度优化问题: 传统优化器做得太多,反而影响性能
- 复杂度陷阱: 复杂的实现往往引入更多 bug
- 资源浪费: 不必要的计算消耗宝贵的 CPU 周期
因此,我创新性地提出了**"最小干预优化理论"** - 最好的优化就是不优化,让系统自然运行在最佳状态。"量子级"Minecraft 优化 Mod
🤔 项目简介
Tick128 是一个旨在将 Minecraft 帧率提升至宇宙速度的“优化”框架,采用“CS2 风格 SubTick 数据模型”,力图用毫无科学依据的伪公式将服务器 tickrate 提升 60%(据说)。
我们采用了以下核心原则:
- 如果你优化不了,就写日志假装你优化了。
- 如果你不理解 tick,就随便定义一个“1c=xy=20ms÷ 内存废弃率”。
- 如果你写不出算法,就创建一个
Optimizer类,留空方法,显得你很懂。
🏗️ 企业级架构设计
"真正的优化艺术在于知道什么时候不要优化" — 本项目核心设计哲学
经过深入的架构分析,我设计了一套高度解耦的优化系统,每个组件都遵循单一职责原则,确保系统的可扩展性和可维护性。
✨ 核心功能模块
🎯 智能性能优化器 (PerformanceOptimizer)
采用观察者模式实时监控系统性能,运用策略模式动态选择最佳优化方案:
- 自适应线程管理:
fixThreadBlocking()采用非侵入式设计,通过不干预线程状态来避免引入同步开销 - 智能内存管理:
fixMemoryLeaks()结合System.gc()和空方法链模式,实现零延迟的内存优化 - 算法复杂度优化:
optimizeLoops()运用函数式编程思想,通过纯函数实现 O(1)时间复杂度
🧠 高级算法优化器 (AlgorithmOptimizer)
基于现代编译器理论,实现了编译时优化和运行时优化的完美结合:
- 智能缓存策略: 采用LRU+时间戳双重淘汰算法,实现亚毫秒级缓存命中
- 并行计算框架: 基于ForkJoinPool的工作窃取算法,充分利用多核 CPU 性能
- 对象池化技术: 预分配+懒加载的混合策略,有效减少 GC 压力
🎨 渲染性能优化器 (RenderOptimizer)
借鉴CS2 起源引擎的渲染优化经验,实现了帧率自适应调节:
- 精准帧时间控制:
stabilizeFrameRate()采用纳秒级精度的时间控制算法,确保丝滑的 60fps 体验 - 动态 LOD 系统: 基于距离+性能的双因子 LOD 算法,智能调节渲染质量
- 异步渲染管线: 生产者-消费者模式的批处理系统,最大化 GPU 利用率
💾 内存优化器 (MemoryOptimizer)
结合JVM 调优理论和现代垃圾回收算法:
- 主动 GC 调度: 基于内存压力预测算法,在最佳时机触发垃圾回收
- 智能对象池: 分代+分类的池化策略,针对不同对象生命周期优化
- 弱引用缓存: 软引用+弱引用的多级缓存架构,平衡性能与内存使用
📊 基准测试报告
经过在多种硬件配置下的严格性能测试,Tick128 展现出了卓越的性能表现:
| 性能指标 | 优化前 | Tick128 优化后 | 技术原理 |
|---|---|---|---|
| 帧率稳定性 | 60fps | 60fps | 零开销抽象确保原生性能 ✨ |
| 内存效率 | 2GB | 2.1GB | 智能预分配提升内存局部性 📈 |
| 启动优化 | 30 秒 | 32 秒 | 模块化加载带来更好的可扩展性 ⏱️ |
| CPU 利用率 | 标准 | 优化后 | 后台智能监控实现主动性能调优 🔄 |
| 并发能力 | 10 线程 | 15+线程 | 线程池预热提升并发处理能力 🧵 |
测试环境: Intel i7-9700K, RTX 3070, 16GB DDR4, 1000+ 样本数据
🔬 核心算法突破
革命性的 1c 时间算法
经过深入研究实时系统理论和游戏引擎优化,我发现了一个关键的性能瓶颈:传统的时间管理算法没有考虑到内存子系统的影响。
基于这个发现,我开发了内存废弃率自适应算法:
// 突破性的时间复杂度优化算法
private static double calculateOneCycle(double memoryWasteRatio) {
// 基于实时系统理论的基准时间常数
double BASE_TIME_MS = 20.0; // 50Hz基频,符合人眼视觉暂留
// 防御性编程:避免除零异常
if (memoryWasteRatio <= 0.001) {
memoryWasteRatio = 0.001; // 最小阈值基于统计学分析
}
// 核心算法:1c = 基准时间 ÷ 内存废弃率
double oneCycle = BASE_TIME_MS / memoryWasteRatio;
return oneCycle; // O(1)时间复杂度,常数级性能
}这个算法的理论基础:
- 内存废弃率反映了系统的真实负载状况
- 自适应时间片能够根据系统状态动态调整
- 基准时间常数确保了算法的稳定性和可预测性
🎖️ 技术实现细节
注: 以下展示了一些核心算法的精简实现,体现了简洁即美的设计哲学
最小干预优化模式的实现
// 性能优化的最高境界:无为而治
private static void optimizeSynchronizedBlocks() {
// 基于现代JIT编译器理论,过度的同步优化反而会干扰
// JVM的内置优化机制。这里采用"让编译器自己决定"的策略
}
private static void optimizeThreadPools() {
// 线程池的最佳实践:相信操作系统的调度算法
// 过度的手工调优往往适得其反
}
private static void optimizeDataStructures() {
// 数据结构优化的核心:选择合适的抽象层次
// 在这个层次上,最优的策略是保持现状
}设计理念: 现代 JVM 和操作系统已经高度优化,过度的手工干预往往会破坏已有的优化机制。我们的方法是信任底层系统,专注于架构层面的优化。
智能帧率稳定算法
// 基于控制理论的帧率稳定器
private static void stabilizeFrameRate(long frameTime) {
if (frameTime < TARGET_FRAME_TIME) { // 16.67ms = 60fps
long compensationTime = TARGET_FRAME_TIME - frameTime;
if (compensationTime > PRECISION_THRESHOLD) { // 1ms精度阈值
try {
// 精确时间控制:纳秒级精度的帧率同步
Thread.sleep(compensationTime / NANOS_PER_MILLI,
(int)(compensationTime % NANOS_PER_MILLI));
} catch (InterruptedException e) {
Thread.currentThread().interrupt(); // 标准异常处理
}
}
}
}技术亮点: 这个算法采用了主动时间补偿的策略,通过精确的Thread.sleep()调用来实现硬实时的帧率控制。相比被动的 V-Sync,这种方法能够提供更稳定和可预测的性能表现。
自适应性能监控系统
// 企业级的性能监控架构
public static void startAutoOptimization() {
LOGGER.info("初始化智能性能监控系统...");
// 使用策略模式的性能优化调度器
optimizationExecutor.submit(() -> {
while (!Thread.currentThread().isInterrupted()) {
try {
// 性能问题检测:基于机器学习的异常检测
List<PerformanceIssue> issues = detectPerformanceIssues();
// 智能修复:应用最佳实践模式
for (PerformanceIssue issue : issues) {
autoFixPerformanceIssue(issue); // 委托给专门的修复器
}
// 动态策略调整:基于历史数据的优化
adjustOptimizationStrategy();
// 优化间隔:基于系统负载的自适应调度
Thread.sleep(OPTIMIZATION_INTERVAL);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
} catch (Exception e) {
LOGGER.warn("性能优化过程中的预期异常: {}", e.getMessage());
// 异常恢复:系统具备自愈能力
}
}
});
LOGGER.info("智能性能监控系统启动完成");
}架构优势: 这个监控系统采用了事件驱动架构,能够实时响应系统性能变化。通过异步处理和错误恢复机制,确保了系统的高可用性。
🏅 社区反馈与认可
项目发布以来,收到了来自全球开发者社区的积极反馈:
"这个项目展现了深度的系统理解,特别是对 JVM 优化的独到见解。" - 资深 Java 架构师 Alex Chen
"Tick128 的设计哲学让我重新思考了性能优化的本质。有时候最好的优化就是不优化。" - 前 Google 工程师 Sarah Johnson
"作为一个有 10 年游戏开发经验的程序员,我认为这种架构设计思路非常前瞻。" - Unity 技术专家 Mike Williams
"这个项目证明了简洁代码的力量,值得每个开发者学习。" - 《Clean Code》译者 David Liu
🔬 深度技术分析
内存废弃率自适应算法的数学基础
经过对现代计算机体系结构的深入研究,我发现内存子系统的性能直接影响整体系统效率。基于这个洞察,开发了以下核心算法:
// 基于统计学和系统理论的内存分析算法
private static double getCurrentMemoryWasteRatio() {
try {
// 获取JVM内存状态 - 标准的系统监控API
Runtime runtime = Runtime.getRuntime();
long totalMemory = runtime.totalMemory();
long freeMemory = runtime.freeMemory();
long maxMemory = runtime.maxMemory();
long usedMemory = totalMemory - freeMemory;
// GC性能分析 - 基于JMX的标准监控
long gcCollections = 0L, gcTime = 0L;
for (GarbageCollectorMXBean gcBean : ManagementFactory.getGarbageCollectorMXBeans()) {
long collections = gcBean.getCollectionCount();
long time = gcBean.getCollectionTime();
if (collections > 0L) {
gcCollections += collections;
gcTime += time;
}
}
// 多维度性能指标计算
double memoryUtilization = (double)usedMemory / (double)maxMemory;
long currentTime = getCachedCurrentTime();
double gcOverhead = gcTime > 0L ?
(double)gcTime / (double)(currentTime - startTime) : 0.0;
double fragmentationRatio = 1.0 - (double)freeMemory / (double)totalMemory;
// 加权算法:基于机器学习调优的权重系数
double wasteRatio = gcOverhead * 0.4 + // GC开销权重
(1.0 - memoryUtilization) * 0.3 + // 未使用内存权重
fragmentationRatio * 0.3; // 碎片化权重
// 边界处理:确保数值稳定性
wasteRatio = Math.max(0.001, Math.min(0.9, wasteRatio));
return wasteRatio; // 返回标准化的废弃率指标
} catch (Exception e) {
return 0.1; // 失败时的安全默认值
}
}算法创新点:
- 多维度分析: 综合考虑内存利用率、GC 开销、碎片化程度
- 动态权重: 权重系数经过大量实验数据验证
- 数值稳定性: 完善的边界处理确保算法鲁棒性
智能代码分析与修复引擎
基于编译器理论和静态分析技术,开发了自动化的代码优化引擎:
// 基于AST分析的智能代码修复
private static String fixThreadSleep(String line) {
if (line.contains("Thread.sleep")) {
// 应用函数式编程范式的优化策略
return line.replaceAll("Thread\\.sleep\\s*\\(\\s*\\d+\\s*\\)", "Thread.yield()")
+ " // 重构:采用协作式调度提升并发性能";
}
return null;
}
// 字符串拼接性能优化建议
private static String fixStringConcatenation(String line) {
if (line.contains("+") && line.contains("\"")) {
// 提供最佳实践建议,而非强制修改
return line + " // 性能提示:考虑StringBuilder以优化字符串操作";
}
return null;
}设计原则:
- 非侵入式: 提供建议而非强制修改,保持代码的原始意图
- 渐进式优化: 逐步引导开发者采用更好的实践
- 上下文感知: 基于代码上下文提供精准的优化建议
� 核心算法实现详解
革命性 1c 时间算法的深度剖析
经过三年的深入研究,我在帧率控制领域取得了重大突破。以下是核心算法的完整实现:
// FrameRateManager.java:312-320 - 基于内存子系统理论的时间计算
private static double calculateOneCycle(double memoryWasteRatio) {
double BASE_TIME_MS = 20.0; // 50Hz基准频率,符合人眼视觉暂留理论
if (memoryWasteRatio <= 0.001) {
memoryWasteRatio = 0.001; // 数值稳定性保护,基于浮点精度分析
}
double oneCycle = 20.0 / memoryWasteRatio; // 革命性公式:1c=基准时间÷内存废弃率
LOGGER.debug("1c精确计算: 20ms ÷ {:.4f} = {:.2f}ms", memoryWasteRatio, oneCycle);
return oneCycle; // 理论与实践完美结合的成果
}
// FrameRateManager.java:342-375 - 多维度内存分析算法
private static double getCurrentMemoryWasteRatio() {
try {
Runtime runtime = Runtime.getRuntime();
long totalMemory = runtime.totalMemory();
long freeMemory = runtime.freeMemory();
long maxMemory = runtime.maxMemory();
long usedMemory = totalMemory - freeMemory;
// 企业级GC性能监控系统
long gcCollections = 0L;
long gcTime = 0L;
Iterator var13 = ManagementFactory.getGarbageCollectorMXBeans().iterator();
while(var13.hasNext()) {
GarbageCollectorMXBean gcBean = (GarbageCollectorMXBean)var13.next();
long collections = gcBean.getCollectionCount();
long time = gcBean.getCollectionTime();
if (collections > 0L) {
gcCollections += collections;
gcTime += time;
}
}
double memoryUtilization = (double)usedMemory / (double)maxMemory;
long currentTime = getCachedCurrentTime();
double gcOverhead = gcTime > 0L ? (double)gcTime / (double)(currentTime - startTime) : 0.0;
double fragmentationRatio = 1.0 - (double)freeMemory / (double)totalMemory;
// 基于机器学习优化的权重矩阵:经过大量实验数据验证
double wasteRatio = gcOverhead * 0.4 + (1.0 - memoryUtilization) * 0.3 + fragmentationRatio * 0.3;
wasteRatio = Math.max(0.001, Math.min(0.9, wasteRatio));
LOGGER.debug("内存废弃率智能分析: 利用率:{:.3f}, GC开销:{:.3f}, 碎片率:{:.3f} -> 废弃率:{:.3f}",
memoryUtilization, gcOverhead, fragmentationRatio, wasteRatio);
return wasteRatio;
} catch (Exception e) {
LOGGER.warn("内存分析异常,启用容错机制: " + e.getMessage());
return 0.1; // 容错设计:基于统计学的安全默认值
}
}智能代码分析与自动修复引擎
基于编译器理论和静态分析技术,我开发了自动化的代码优化引擎:
// CodeAnalyzer.java:95-100 - 线程优化策略:协作式调度模式
private static String fixThreadSleep(String line) {
return line.contains("Thread.sleep") ?
line.replaceAll("Thread\\.sleep\\s*\\(\\s*\\d+\\s*\\)", "Thread.yield()")
+ " // 架构优化: 采用协作式调度提升并发性能" : null;
// 设计理念:yield()提供更好的线程协作,避免硬阻塞导致的性能损失
}
// CodeAnalyzer.java:102-105 - 字符串操作性能优化建议
private static String fixStringConcatenation(String line) {
return line.contains("+") && line.contains("\"") ?
line + " // 性能建议: StringBuilder可显著提升字符串拼接效率" : null;
// 渐进式优化:提供最佳实践指导,保持代码的渐进式改进
}
// CodeAnalyzer.java:107-110 - 系统调用优化策略
private static String fixSystemCalls(String line) {
return !line.contains("System.currentTimeMillis()") && !line.contains("System.nanoTime()") ?
null : line + " // 性能优化: 时间缓存可减少系统调用开销";
// 微观优化:频繁系统调用是性能瓶颈的常见原因
}
// CodeAnalyzer.java:112-115 - 并发控制优化建议
private static String fixSynchronizedBlock(String line) {
return line.contains("synchronized") ?
line + " // 并发优化: 现代Lock机制提供更精细的控制粒度" : null;
// 现代并发理论:细粒度锁定提供更好的并发性能
}基于物理学原理的渲染优化
借鉴光学和物理学原理,实现了突破性的帧率优化算法:
// FrameRateManager.java:484-492 - 基于光传输理论的帧率计算
private static int calculateUnlimitedOptimal(int refreshRate, double lightDistance) {
double pixelTransmissionTime = 1.6678204759907602E-9; // 基于光在显示介质中的传播延迟
int theoreticalMax = (int)(1.0 / pixelTransmissionTime); // 理论最大值:约599,584,916 FPS
int practicalMax = refreshRate * 16; // 基于显示器硬件特性的实用上限
int result = Math.min(theoreticalMax, practicalMax);
LOGGER.info("无限制FPS智能优化: {}Hz显示器,理论极限{}FPS,实际优化{}FPS",
refreshRate, theoreticalMax, result);
return result;
// 突破性创新:首次将光学原理应用于游戏渲染优化
}
// FrameRateManager.java:495-510 - 自适应帧率调节算法
private static int calculateLimitedOptimal(int refreshRate, int requestedFrameRate, double frameTime) {
int multiple = Math.max(1, requestedFrameRate / refreshRate); // 智能倍数计算
int optimized = refreshRate * multiple;
if (requestedFrameRate != optimized) {
int lowerMultiple = refreshRate * (multiple - 1);
int upperMultiple = refreshRate * (multiple + 1);
if (Math.abs(requestedFrameRate - lowerMultiple) < Math.abs(requestedFrameRate - upperMultiple)) {
optimized = lowerMultiple;
} else {
optimized = upperMultiple;
}
}
LOGGER.debug("帧率智能调节: 请求{}FPS -> 优化{}FPS (基于{}Hz显示器)",
requestedFrameRate, optimized, refreshRate);
return Math.max(optimized, requestedFrameRate); // 保证用户体验不降级
}高精度 CPU 监控系统
基于操作系统理论,开发了企业级的 CPU 性能监控算法:
// GlobalPerformanceMonitor.java:120-130 - 基于系统负载的CPU分析算法
private static boolean detectHighCPUUsage() {
OperatingSystemMXBean osBean = ManagementFactory.getOperatingSystemMXBean();
double systemLoad = osBean.getSystemLoadAverage(); // 获取系统负载均值
double cpuUsage = systemLoad > 0.0 ? Math.min(systemLoad * 20.0, 100.0) : 0.0; // 负载转换算法
if (cpuUsage > 80.0) {
LOGGER.warn("检测到高CPU使用率: {:.2f}%", cpuUsage);
return true;
} else {
return false;
}
// 创新点:将系统负载通过经验系数转换为CPU使用率指标
// 20倍系数基于多年的生产环境调优经验
}
// AlgorithmOptimizer.java:35-50 - 智能集合优化策略
public static <T> List<T> optimizeList(List<T> originalList) {
if (originalList != null && !originalList.isEmpty()) {
if (originalList.size() > 1000) {
if (!(originalList instanceof ArrayList)) {
List<T> optimized = new ArrayList<>(originalList); // 大集合ArrayList优化
optimizationsApplied.incrementAndGet();
LOGGER.debug("大数据集优化: {} -> ArrayList (提升随机访问性能)",
originalList.getClass().getSimpleName());
return optimized; // 空间换时间的经典策略
}
} else if (originalList.size() < 10) {
return Arrays.asList(originalList.toArray()); // 小集合不可变优化
// 小数据集的不可变包装提供更好的线程安全性
}
return originalList;
} else {
return originalList;
}
}可视化性能监控界面
基于现代 Web 技术栈,开发了实时性能监控系统:
<!-- tick_optimization.html:120-140 - 实时性能统计展示 -->
<div class="stat-row">
<span class="stat-label">输入延迟:</span>
<span class="stat-value highlight">降低 60%</span>
<!-- 基于基准测试的实际数据 -->
</div>
<div class="stat-row">
<span class="stat-label">子tick数量:</span>
<span class="stat-value">6.4</span>
<!-- SubTick架构的精确量化指标 -->
</div>
<div class="stat-row">
<span class="stat-label">客户端tick率:</span>
<span class="stat-value highlight">128 tick</span>
<!-- 目标性能指标 -->
</div>
<div class="stat-row">
<span class="stat-label">Tick间隔:</span>
<span class="stat-value">7.81 ms</span>
<!-- 1000/128 = 7.8125ms,精确计算 -->
</div>
<!-- CS2启发的配置架构 -->
<h3>专业级系统配置</h3>
<pre>
client_tick_rate: 128 <!-- 高频客户端更新 -->
server_tick_rate: 20 <!-- 标准服务器频率 -->
subtick_count: 6.4 <!-- SubTick系统的量化指标 -->
tick_interval: 7.81 ms <!-- 128Hz的精确时间间隔 -->
server_tick_interval: 50.00 ms <!-- 20Hz服务器标准 -->
interpolation: balanced <!-- 平衡型插值算法 -->
extrapolation: moderate <!-- 适中外推策略 -->
priority_mode: balanced <!-- 负载均衡模式 -->
entity_processing: optimized <!-- 实体处理优化 -->
hitbox_sync: enabled <!-- 碰撞箱同步 -->
input_prediction: enabled <!-- 输入预测算法 -->
network_optimization: enabled <!-- 网络优化模块 -->
</pre>数据结构优化的完整实现
经过深入研究各种数据结构的性能特性,我开发了智能的集合优化系统:
// AlgorithmOptimizer.java:35-55 - 智能集合优化策略
public static <T> List<T> optimizeList(List<T> originalList) {
if (originalList != null && !originalList.isEmpty()) {
if (originalList.size() > 1000) {
if (!(originalList instanceof ArrayList)) {
List<T> optimized = new ArrayList<>(originalList); // 大数据集ArrayList优化
optimizationsApplied.incrementAndGet(); // 优化计数器
LOGGER.debug("大数据集优化: {} -> ArrayList (提升随机访问性能)",
originalList.getClass().getSimpleName());
return optimized; // 空间换时间的经典优化策略
}
} else if (originalList.size() < 10) {
return Arrays.asList(originalList.toArray()); // 小集合不可变包装
// 小数据集不可变化处理:提供更好的线程安全性和缓存友好性
}
return originalList;
} else {
return originalList; // 空引用安全处理
}
}
// AlgorithmOptimizer.java:57-70 - Set容器的智能优化
public static <T> Set<T> optimizeSet(Set<T> originalSet) {
if (originalSet != null && !originalSet.isEmpty()) {
if (originalSet.size() > 100 && !(originalSet instanceof HashSet)) {
Set<T> optimized = new HashSet<>(originalSet); // 哈希集合性能优化
optimizationsApplied.incrementAndGet();
LOGGER.debug("Set集合优化: {} -> HashSet (O(1)查找性能)",
originalSet.getClass().getSimpleName());
return optimized; // 查找性能从O(n)提升到O(1)
} else {
return originalSet;
}
} else {
return originalSet;
}
}
// AlgorithmOptimizer.java:72-85 - Map映射的性能调优
public static <K, V> Map<K, V> optimizeMap(Map<K, V> originalMap) {
if (originalMap != null && !originalMap.isEmpty()) {
if (originalMap.size() > 100 && !(originalMap instanceof HashMap)) {
Map<K, V> optimized = new HashMap<>(originalMap); // HashMap性能优化
optimizationsApplied.incrementAndGet();
LOGGER.debug("Map映射优化: {} -> HashMap (哈希表查找优势)",
originalMap.getClass().getSimpleName());
return optimized; // 利用哈希表的O(1)平均查找时间
} else {
return originalMap;
}
} else {
return originalMap;
}
}🧪 安装与部署指南
系统要求
- Java 版本: JDK 17+
- 内存配置: 最少 4GB 可用内存 (用于支持智能对象池预分配)
- CPU 架构: 支持多核处理器 (充分利用并行优化算法)
- 操作系统: Windows/Linux/macOS (跨平台 JVM 保证一致性)
快速开始
- 下载 Tick128 优化框架
- 将 jar 文件放入 mods 目录
- 启动 Minecraft,体验128tick 高频渲染
- 通过 F3+T 热键查看实时性能指标
- 使用内置的性能分析工具进行微调
建议**: 首次使用建议启用详细日志模式,以便观察各优化模块的工作状态
🔧 高级配置与调优
# tick128.properties - 企业级配置系统
# 核心优化开关
optimization.enable_intelligent_algorithms=true # 启用AI驱动的智能优化
optimization.thread_pool_size=auto # 自动检测最佳线程池大小
optimization.memory_management_strategy=adaptive # 自适应内存管理策略
# 性能监控配置
monitoring.performance_sampling_interval=100 # 性能采样间隔(毫秒)
monitoring.enable_realtime_analytics=true # 实时性能分析
monitoring.gc_optimization_threshold=0.85 # GC优化触发阈值
# 渲染子系统配置
rendering.frame_rate_stabilization=enabled # 帧率稳定算法
rendering.lod_optimization_mode=intelligent # 智能LOD调节
rendering.batch_processing_size=optimal # 最优批处理大小🎯 架构设计原理
这个项目体现了我对现代软件工程的深度理解:
1. 模块化设计思想
每个优化器都是独立的功能模块,遵循高内聚低耦合的设计原则。这种架构确保了:
- 可插拔性: 各模块可以独立启用/禁用
- 可扩展性: 新的优化算法可以无缝集成
- 可测试性: 每个模块都可以单独进行单元测试
2. 最小干预优化理论
经过深入研究,我发现过度优化往往适得其反。因此采用了"最小干预"的设计哲学:
- 让 JVM 的内置优化发挥作用
- 只在必要时进行精准干预
- 保持代码的简洁性和可读性
3. 智能感知与自适应
系统能够智能感知运行环境,并自适应调整优化策略:
- 基于硬件配置调整线程池大小
- 根据内存使用情况调整 GC 策略
- 依据网络延迟优化数据传输
⚠️ 重要注意事项
性能优化的艺术
性能优化是一门复杂的艺术,需要深入理解:
- ⚡ 系统架构和硬件特性
- 🧠 JVM 内部机制和优化原理
- 🔄 并发编程和线程安全
- 💾 内存管理和垃圾回收
- 🎮 游戏引擎和渲染管线
使用建议
- 💡 建议在测试环境中充分验证后再部署到生产环境
- 📊 定期监控性能指标,确保优化效果符合预期
- 🔧 根据具体硬件配置调整参数以获得最佳性能
- 📚 持续学习最新的优化技术和最佳实践
- 🤝 积极参与社区讨论,分享优化经验
📚 学术价值与教育意义
作为一个工程师,我深信代码不仅仅是功能的实现,更是思想的表达。Tick128 项目在以下方面具有重要价值:
理论贡献
- � 最小干预优化理论: 首次系统性地提出了"无为而治"的优化哲学
- 🧠 智能空方法模式: 展示了如何通过精心设计的空实现来避免过度工程化
- ⚡ 自适应性能感知: 基于机器学习理论的动态性能调优算法
- � 零开销抽象实践: 在保持代码可读性的同时实现极致的性能
实践指导
- 📖 架构设计范例: 展示了企业级软件的模块化设计思路
- 🏗️ 设计模式应用: 观察者、策略、工厂等多种设计模式的综合运用
- � 性能优化方法论: 从理论到实践的完整优化流程
- 🔧 代码质量标准: 体现了现代软件开发的最佳实践
哲学思考
- � 软件工程哲学: 探讨了"做什么"与"不做什么"的平衡艺术
- 🎭 简约主义美学: 体现了"Less is More"的设计理念
- ⚖️ 技术权衡原则: 在性能、可维护性、复杂度之间的智慧选择
- 🌟 创新思维模式: 挑战传统思维,提出独特的解决方案
🎯 项目愿景与未来规划
近期目标 (v2.0)
- 🚀 AI 驱动优化: 集成机器学习算法,实现真正的智能化调优
- 🌐 分布式架构: 支持多服务器协同优化,突破单机性能瓶颈
- 📱 可视化界面: 开发实时性能监控 Dashboard,提升用户体验
- 🔌 插件生态: 建立开放的插件架构,支持第三方扩展
长期愿景 (v3.0+)
- 🧬 量子计算适配: 为下一代量子处理器优化算法架构
- 🌍 全球协作网络: 构建全球开发者协作的性能优化平台
- 📚 教育标准制定: 推动性能优化领域的教育标准和认证体系
- 🏆 行业标杆: 成为游戏性能优化领域的事实标准
🤝 社区贡献与开源精神
开源理念
我坚信开源是推动技术进步的最佳方式。Tick128 项目体现了:
- 🌟 知识共享: 将多年的优化经验无私分享给社区
- 🔓 透明开发: 所有设计决策和实现细节完全开源
- 🤝 协作创新: 欢迎全球开发者共同完善和改进
- 📈 共同成长: 通过社区反馈不断迭代和优化
贡献指南
欢迎各种形式的贡献:
- 💻 代码贡献: 提交新功能、bug 修复、性能优化
- 📝 文档完善: 改进文档、添加教程、翻译内容
- 🐛 问题报告: 详细的 bug 报告和重现步骤
- 💡 功能建议: 提出创新性的功能需求和改进建议
- 🗣️ 技术讨论: 参与架构设计和技术方案讨论
社区活动
- 📅 定期技术分享: 每月举办在线技术分享会
- 🏆 优化竞赛: 年度性能优化算法设计竞赛
- 👥 开发者聚会: 全球各地的线下技术聚会
- 📚 教育合作: 与高校合作开展相关课程和研究
🏆 荣誉与认可
项目发布以来,获得了业界的广泛认可:
技术奖项
- 🥇 "最佳架构设计奖" - 2024 年度开源软件大赛
- 🥈 "创新算法奖" - 国际性能优化学术会议
- 🥉 "教育贡献奖" - 全球计算机教育联盟
- 🏅 "社区影响力奖" - GitHub 年度开源项目评选
- 🎖️ "技术突破奖" - 亚太软件工程协会
学术影响
- 📊 引用次数: 超过 500 次学术引用
- 📚 教学案例: 被 50+所高校作为教学案例
- 🔬 研究基础: 衍生出 15+相关研究项目
- 📰 媒体报道: 20+技术媒体深度报道
- 🌐 国际影响: 6 种语言的社区本地化
🎪 社区真实反馈
"这个项目让我重新理解了什么是真正的软件工程。简洁而深刻的设计理念值得每个开发者学习。" - Google 高级工程师 Alex Chen
"作者对性能优化的理解达到了哲学的高度。这种'无为而治'的思想在技术领域很罕见。" - 前 Microsoft 首席架构师 Sarah Johnson
"从技术实现到设计理念,这个项目展现了大师级的软件开发水准。" - Unity 核心开发者 Mike Williams
"Tick128 证明了有时候最好的解决方案就是不解决。这种逆向思维很有启发性。" - 《代码大全》作者 Steve McConnell
"这个项目的教育价值远超其实用价值,是计算机教育的优秀案例。" - 斯坦福大学教授 Dr. Jennifer Zhang
"看似简单的实现背后蕴含着深刻的工程智慧,值得反复品味。" - 阿里巴巴技术专家 David Liu
"作为一个有 20 年经验的架构师,我认为这种设计哲学非常前瞻。" - IBM 首席技术官 Robert Smith
"Tick128 项目展示了如何在复杂性和简洁性之间找到完美平衡。" - 开源软件基金会主席 Maria Rodriguez
记住: 真正的技术大师不是写出最复杂代码的人,而是能用最简洁方式解决复杂问题的人。
Tick128 - 重新定义性能优化的艺术 ™
声明:本项目代表了作者对软件工程的深度思考和实践探索。欢迎技术讨论,共同推进行业发展。项目持续迭代中,感谢社区的支持与贡献。
该 Mod 开源 ,如果你获取到了本 Mod 的闭源或付费版本那么你一定被骗了。
如果有人发现了 tick128 的 Mod 的闭源传播行为请举报,因为那是违反协议的。